


(Technical) Debt Forgiveness is here

Some background: We have a very large, complex codebase that’s been in production for over 10 years. As you can imagine, with tons of developers working in it, and wanting to move fast - we’ve traded off good architectural decisions and high test coverage for short-term speed. Simple functions like updating a shipping address have grown little weeds on them, as code usually does as we find more edge cases and bugfixes.
I’ve committed my share of sins taking on way too much technical debt over the years. I’ve pushed code with quality I’m not proud of. And bandaid patching known major bugs just to move on to the next feature trying to find product-market fit.
Technical debt has always been something I’d one day get to when times were kinder to us, and I’d always feel guilty about taking it on.
But now, I wish I’d taken on more. Way more.
I’ve been playing around with the AI coding tools, like every other developer recently. We’ve come a long way from copy-pasting code into Claude (a whole 2 months ago), into integrated IDE’s and agenty code-dev tools like Aider / Roo Code / Claude Code.
It’s impossible to tell what’s next, but I love small experiments just to see the edge of our capabilities today.
Inspired by this blog post about agent fleets, and custom modes in RooCode, I’ve been thinking about how we can integrate these new “agents” into existing workflows.
I stumbled upon this custom roo code modes, called rooroo, which uses a local .project_overview.json & local state files for each task (you can try it out to see it in action)
IMO, it’s over-engineered and wastes a lot of tokens to do even the smallest of tasks. But what if we waste even more? Why not use github issues as the state instead of a local file? Take a fairly complex task, break it down, work on each individually, create a branch, push a PR and then read the review comments and work on them.
LLM’s are still not great at working on large codebases, They can’t do the back-and-forth context-learning that any junior developer would do in their place.
RooCode and some custom prompting is the first time I’ve got that “aha” moment on a large codebase where it kind of sometimes does the job right.
Instead of using a JSON file to track tasks and states, why not just use what we’re already used to - github issues, tasks and labels. After all RooCode can already execute tasks on the command line. Just create a few simple wrappers around the github CLI to make issues, add/read comments and labels. Now, we get the advantage of making issues, sub-issues and each one being done in a separate context. The advantage of it being just github issues is that developers can step in to add context, or to re-orient it in the right direction *as it’s running*. I think that’s pretty powerful. Normally, I’d spend a lot of time fighting with it as it goes off the rails. But having it break down the task into regular github issues lets you do an amount of steering that’s impossible in a regular uni-directional prompt. Yes, you can rewind to checkpoints and go back, but doing it once while it’s planning let’s you steer it a lot better, and (b) be more confident that it’ll run longer.
After customizing my own version of rooroo, I think I finally have what it takes to have an autonomous development team that works almost most of the time on refactoring technical debt that I always wanted to but never got around to.
With this, I’ve been successfully able to one-shot pretty complex refactoring task that would have taken probably a month or more of a developers time. Sure, it costs $100 in tokens but there’s something magical about just watching it run for couple hours without asking for instructions and actually eventually working. It creates multiple issues, tags them, adds comments and you’re free to add comments / changes to the tasks. Here’s a screenshot while it’s running:
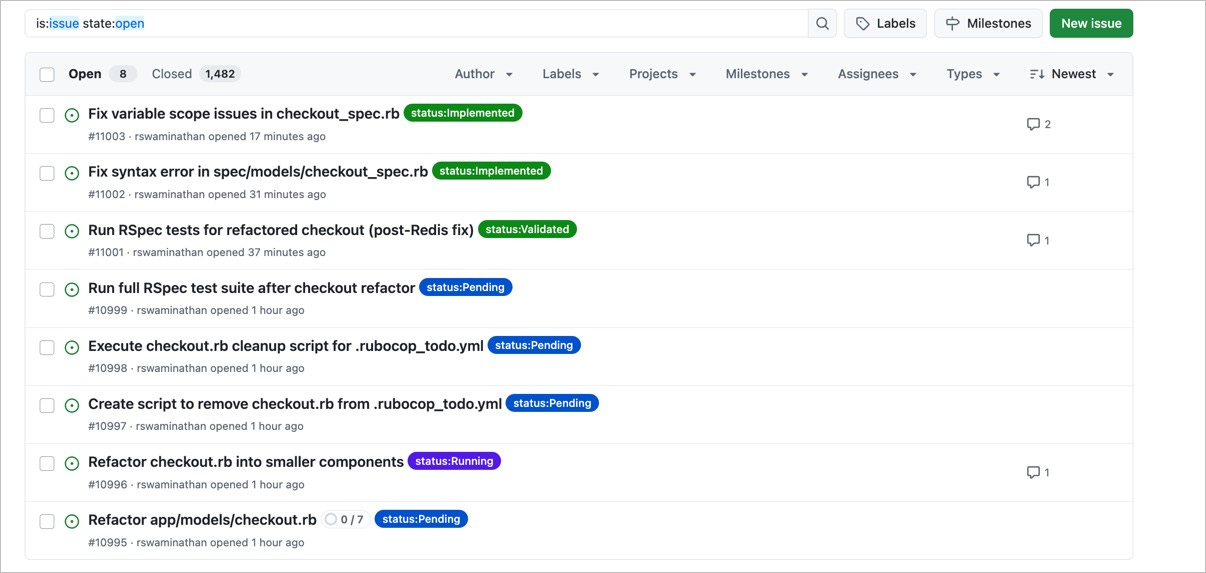
Eventually, it’ll find it’s own bugs that it created, and create new tasks for itself:
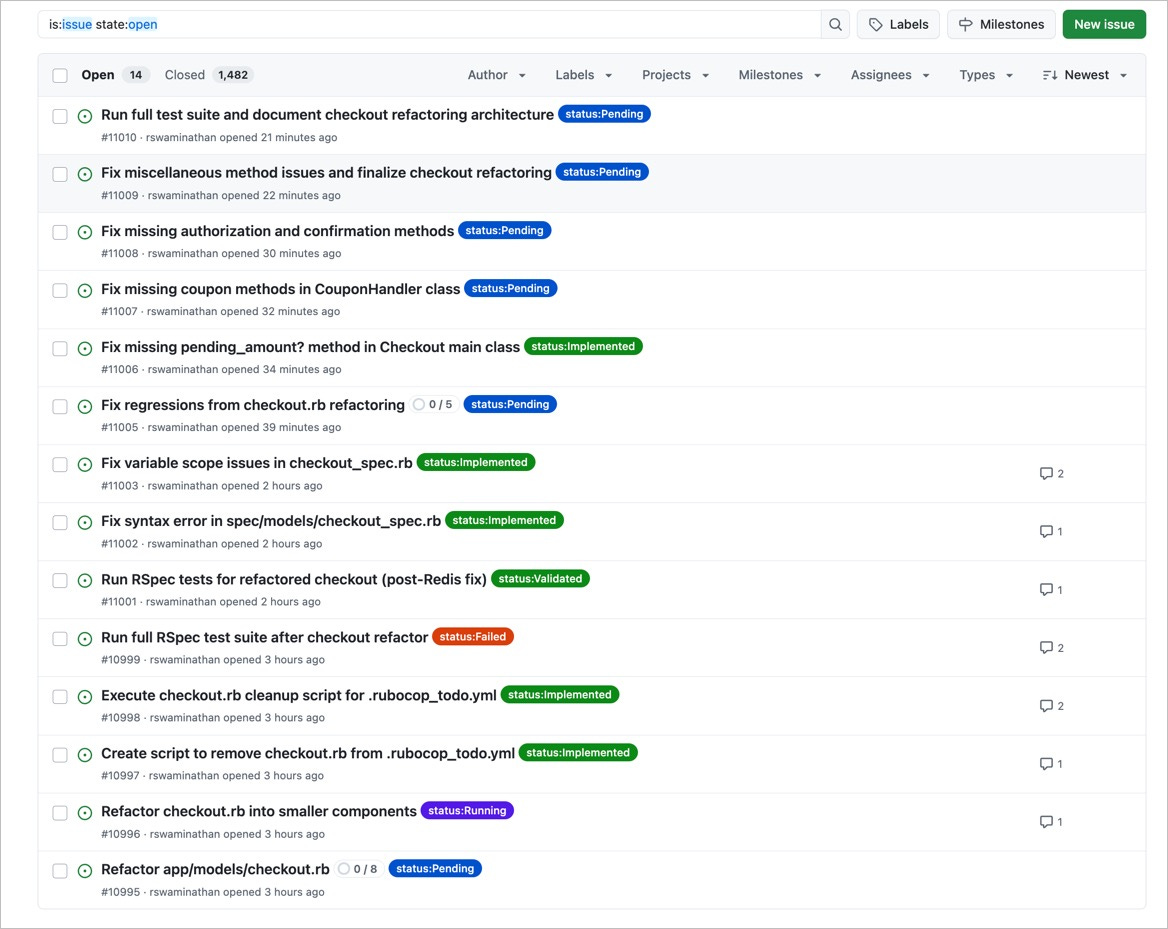
Here’s my updated repo of rooroo modified to work with github issues. I just went through a pretty large refactor (1000+ lines of code in a fairly tangled codebase (100k+ lines).
My last task refactoring ran for almost an 2 hours and it went successfully from a 2 line task to finished, tested fully green CI with no intervention. Having decent tests is really good for anchoring it and letting it find it’s way to the right answers. This would have probably been a 1month project for a mid-level developer.
METR claims that current models are successful at doing tasks that would take humans 1 hour to do. I think that with better orchestration and tooling, we’re probably already at the 1 month mark.
The future is here, it’s just not evenly distributed cheap.
The next step for me would be running this in the cloud, or running multiple instances (RooCode doesn’t have a headless mode yet. And the default prompts seem better than aider / claude code IMO, so I’m not yet willing to make the jump)
I feel like we’re very close to throwing $1k - $10k in tokens at a large codebase (with very little human intervention), and getting out whatever codebase you have minus all the technical debt you’ve always wanted to solve
Performance issues? Just rewrite it in Go.
Old PHP codebase too complex? Rewrite it in typescript and nextjs.
Want to move to microservices? Sure, that’ll be $10,000 and a few days.
Links:
Modified repo (very proof of concept)